ゼミ生みんなの進捗状況を確認するには、いちいちurlを踏まなくてはならない。
全員のを確認するのにurlを40回踏む必要がある。
gitをなかなか更新しない人のサイトを確認する作業は特に無駄になってしまう。(ごめんなさい)
この状態だと知識の共有に繋がりづらい。また興味のある分野の先行している先輩の情報を探すのに苦労してしまう。
どうにかしよう!
今回は完成までの流れをこのサイトや授業で教わった記憶をたどりながらやっていきたいと思う。
大まかに
1要件定義→どんな機能をつけるか
2外部設計→どんな見た目か
3内部設計→中でどう動くか
4プログラミング→実際にコードを書く
5単体テスト→一機能ごとに動作確認
6結合テスト→一つのものにして動作確認
7総合テスト→最後に一から確認
となっています。
大きく分けて機能は二つ。一つ目は、サイトが更新されると通知される機能。
二つ目は、気になるワードから検索できる機能。
今回は一つ目を作っていきたい。
更新した人の名前とurlが表のように表示されるもの。
中でどうやって動いているかを書いていく。
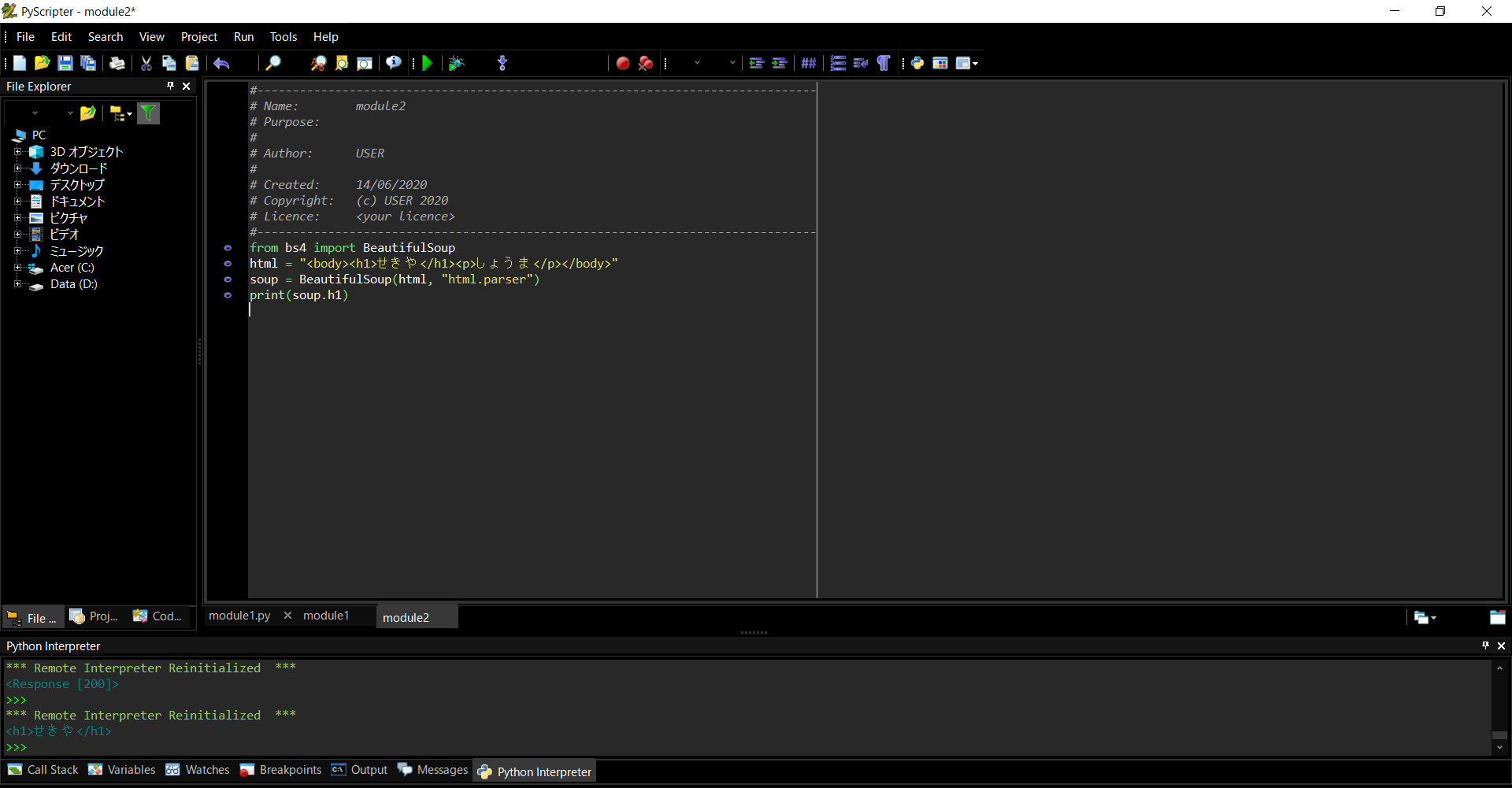
自分たちのhtmlの中にversionという名前をつけたclassを作っておく(2020年6月14日だったら20200614にする)
↓
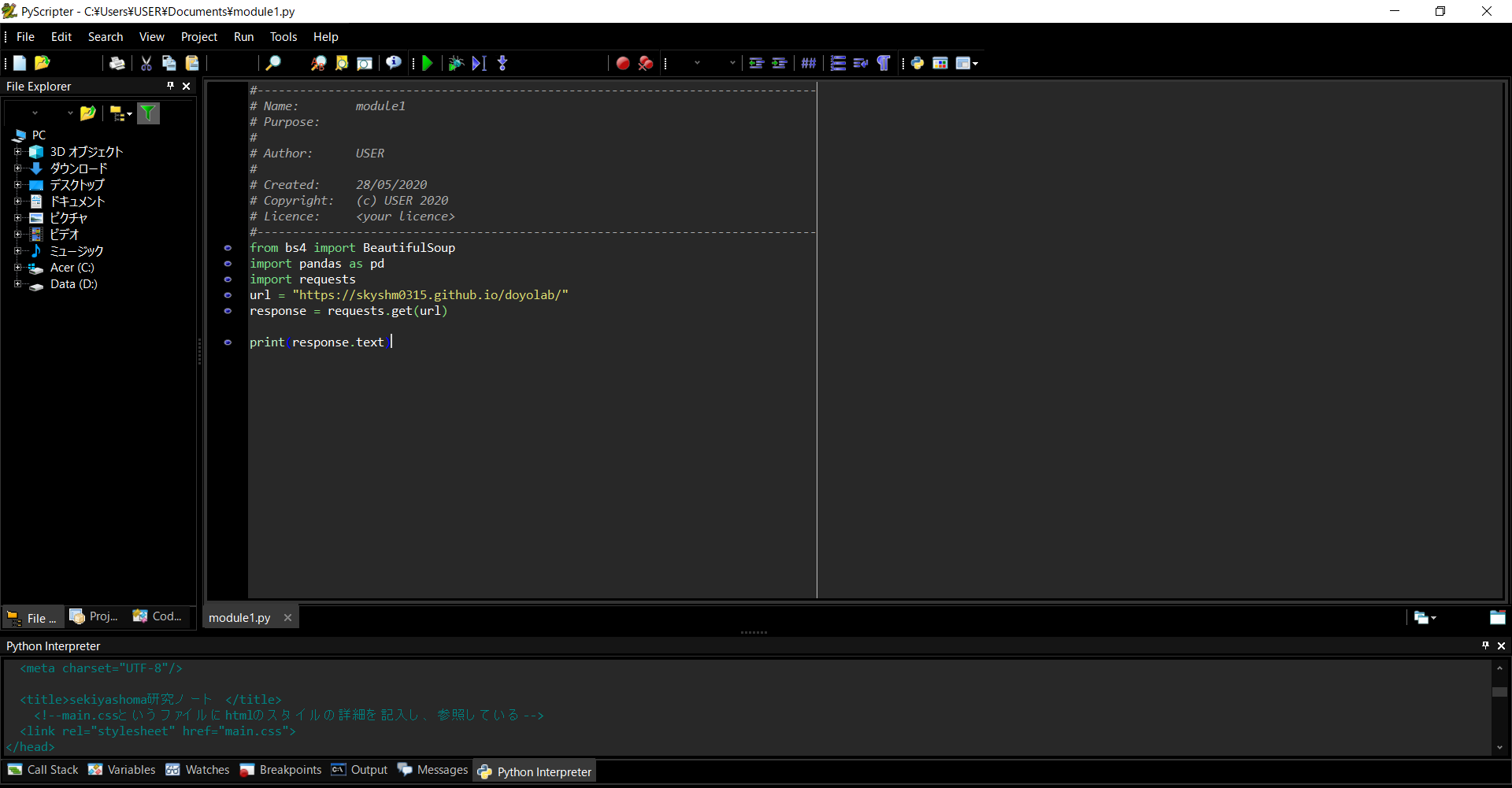
requestというpythonのモジュールを使ってhtmlを取得する。
↓
beautifulsoupというモジュールを使ってこのversionと名前の付けたclassを取得する。
追記、道用先生が送ってくださった記事の方法では、掲示板のような見なくてはならないhtmlが一つだと有効だと思うが、みんなが更新するホームページの都合上、個人でバージョンをつけたほうがよいと思う。
また、上記の記事では前回のhtmlをすべて新しいのと比較する工程があるので全員にそれを行うと処理に時間がかかりすぎるのではないかと懸念しているので、
処理時間についても比較して行きたい。それについても今後gitにあげる。
↓
取得した数字を例えばcsvファイルのようなものに保存する。(メモ帳でいいかもです)
↓
if関数を使う。この取得した番号(20200614)を前回取得した番号と比較して大きければ、言い換えると新しければその人のurlと名前を表示する。
↓
これを自動的に毎日行うようにする。これをクローラーと呼ぶ。
urlとhtmlの取得
htmlの中から特定の要素を取得
解決したエラー
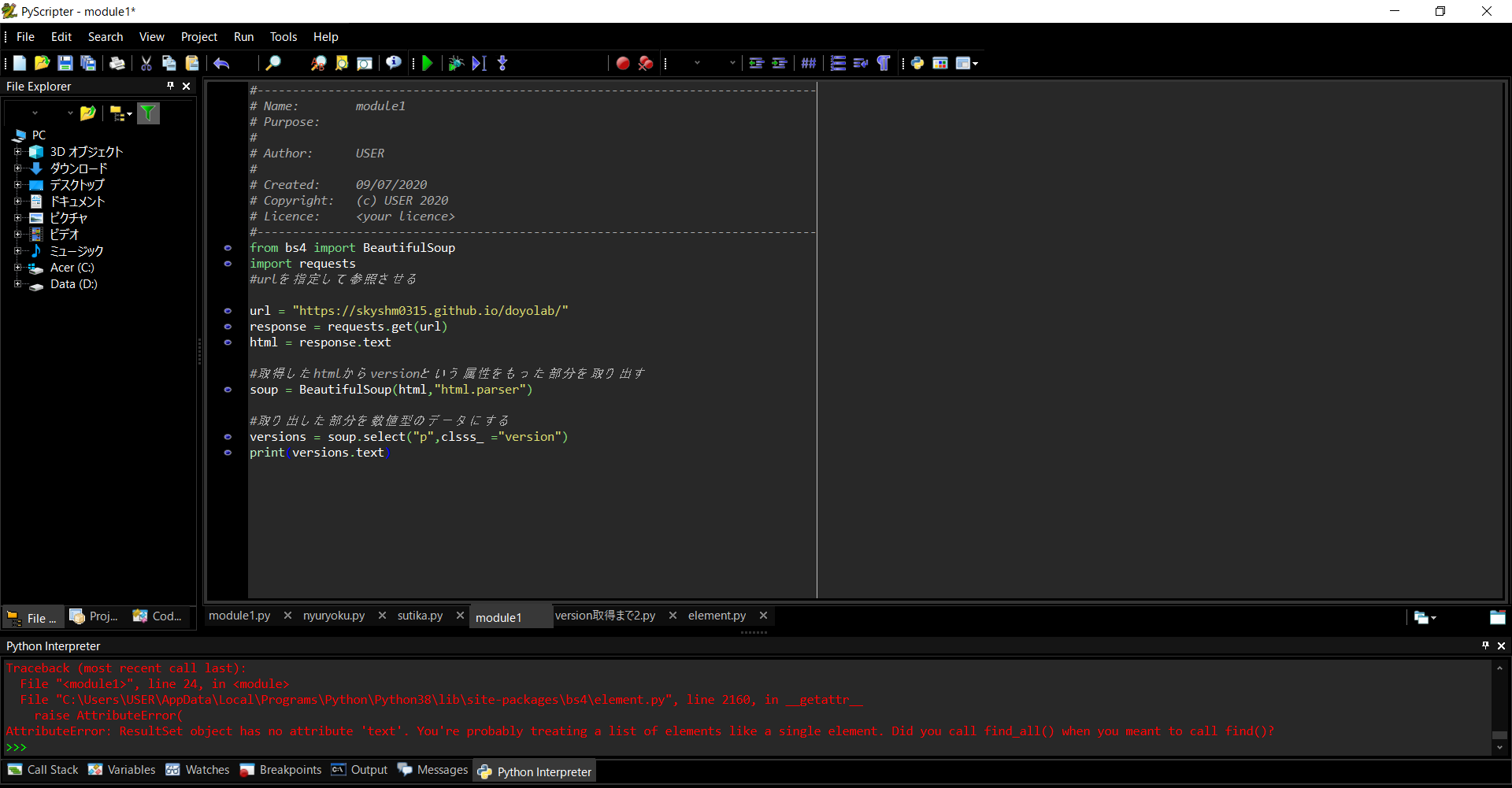
このようにエラーがでてしまった。理由はselectという機能は該当するすべてのものを取り出すものだから。データの型がresultsetというものになる。
そのために、select_oneを使うか、以下の画像の様にselectにはforを使った繰り返し文を使わないといけない。
エラー文の最後に書いてあるように、find_allとfindの間にも同様の関係がある。
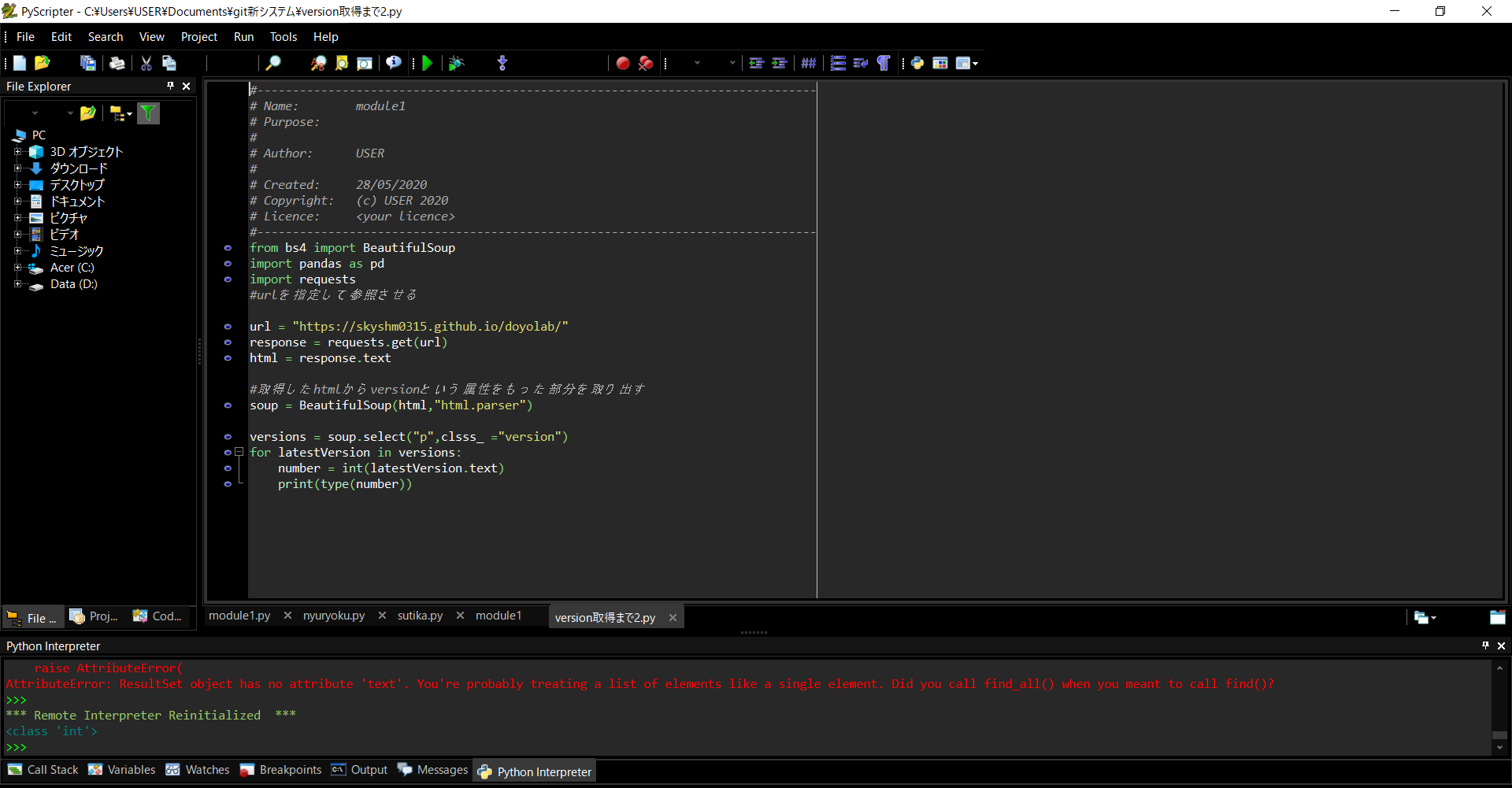
csvファイルから数値を取り出して比較
定期的な実行
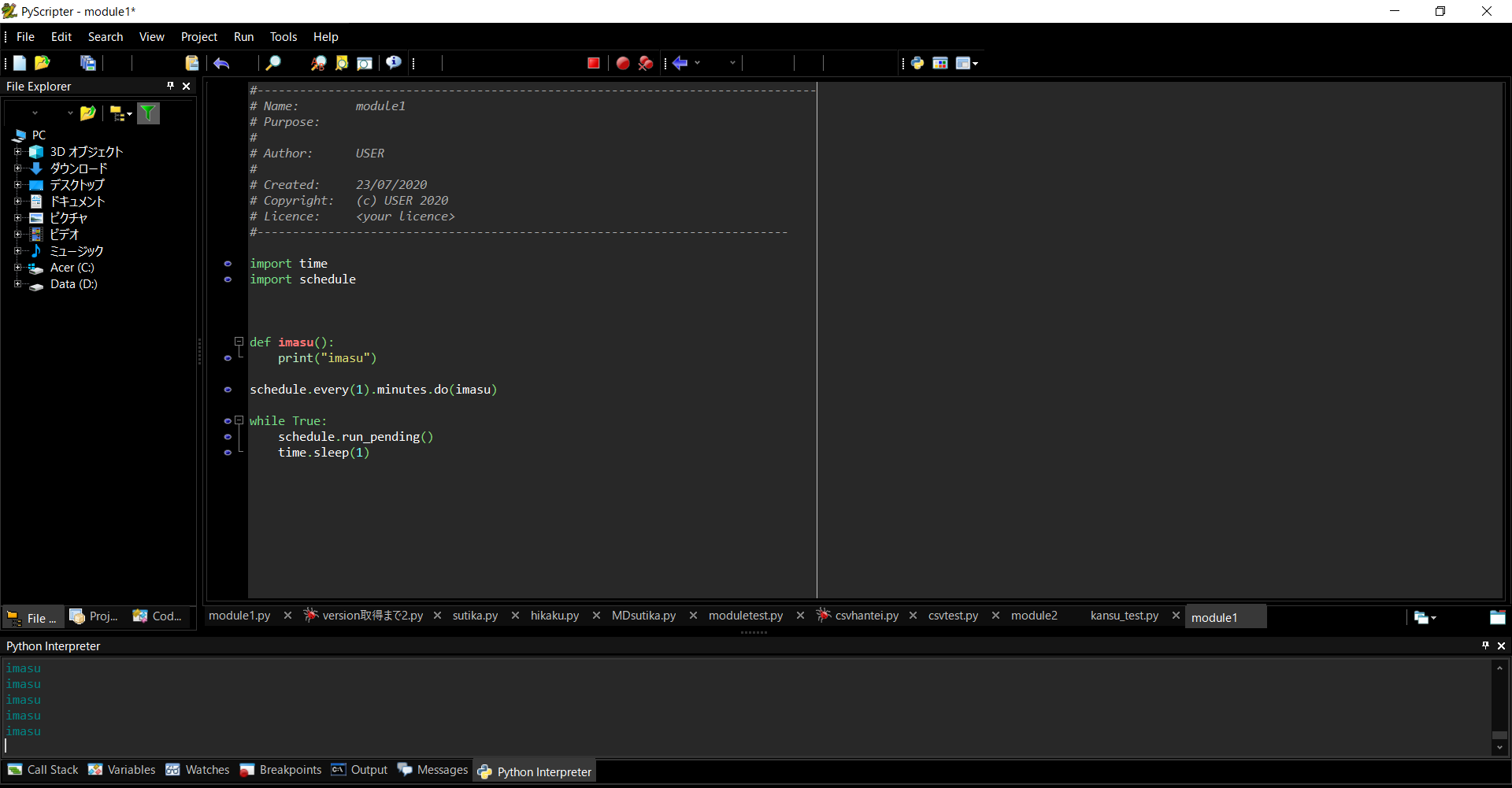
一分おきにimasuという処理ができる